 An artistic visualisation of the cluster analysis technique." width="" height="" />
An artistic visualisation of the cluster analysis technique." width="" height="" />An artistic visualisation of the cluster analysis technique." width="" height="" />
In such scenarios, it’s recommended to separate out these data points based on their similarities to make things easier to start with.
Have you ever heard of cluster analysis ?
It’s an essential way of identifying discrete groups in data among many data professionals, yet many beginners remain in the dark about what cluster analysis is and how it works.
In this blog post, we’ll introduce you to the concept of cluster analysis, its advantages, common algorithms, how they can be evaluated, as well as some real-world applications.
We’ll cover the following:
Join us as we dive into the basics of cluster analysis to help you get started.
To help you better understand cluster analysis, let’s go over the definition of what it is first.
Cluster analysis is a statistical technique that organizes and classifies different objects, data points, or observations into groups or clusters based on similarities or patterns.
You can think of cluster analysis as finding natural groupings in data.
Cluster analysis involves analyzing a set of data and grouping similar observations into distinct clusters, thereby identifying underlying patterns and relationships in the data.
Cluster analysis is widely used in data analytics across various fields, such as marketing, biology, sociology, and image and pattern recognition.
Cluster analysis varies by the type of clustering algorithm used.
The concept of cluster analysis sounds great—but what are its actual advantages?
Here’s a list of them:
Cluster analysis can help to identify groups and relationships in large datasets that may not be readily apparent .
This allows for a deeper understanding of the underlying structure of the data.
Likely the largest benefit of using cluster analysis is the ability to find similarities and differences in large datasets can help identify new trends and opportunities for further research.
Cluster analysis can be used to reduce the complexity of large datasets, making it easier to analyze and interpret the data.
For example, by grouping similar objects together, the number of dimensions of data can be reduced. This might bring benefits of faster and more simplified analysis.
Clustering may also help rule out irrelevant data that do not have similarities. You’ll have a more streamlined analysis process as a result.
Cluster analysis often results in data visualizations of clusters , such as scatterplots or dendrograms.
These visualizations can be powerful tools for communicating complex information. Since cluster plots are simple for most to interpret and understand, this can be a good choice to include in presentations.
As mentioned, when starting a cluster analysis, you’re required to select from one of the appropriate clustering algorithms.
There are quite a few types of clustering algorithms out there, and each of them is used differently.
Here are the five most common types of clustering algorithms you’ll find:
Centroid-based clustering is a type of clustering method that partitions or splits a data set into similar groups based on the distance between their centroids .
Each cluster’s centroid, or center, is determined mathematically as either the mean or median of all the points in the cluster.
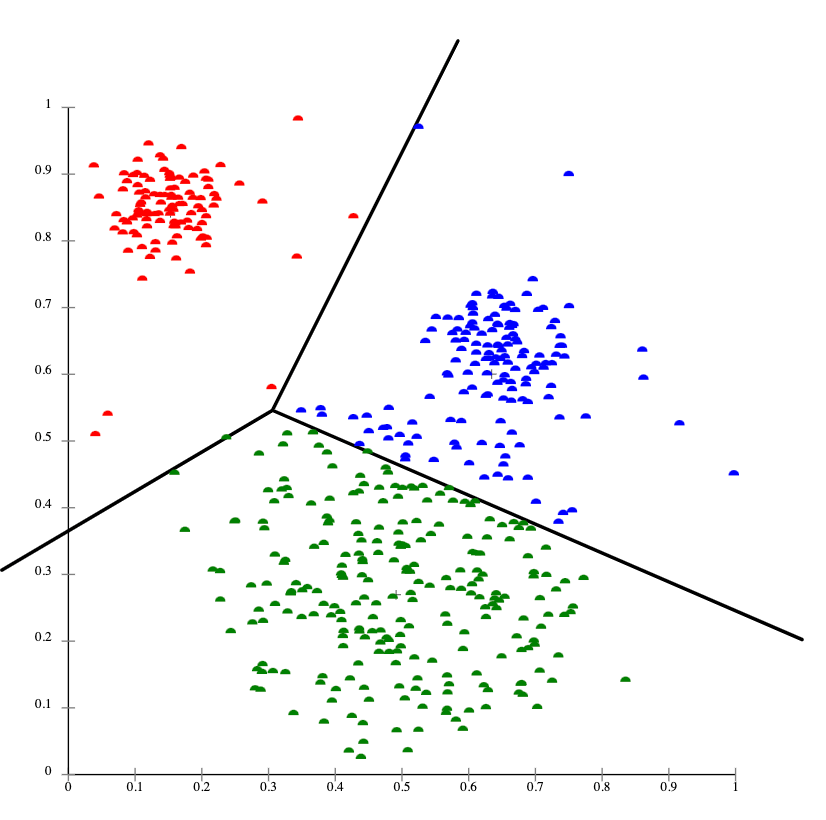
The k-means clustering algorithm is one commonly used centroid-based clustering technique. This method assumes that the center of each cluster represents each cluster.
It aims to find the optimal k clusters in a given data set by iteratively minimizing the total distance between each point and its assigned cluster centroid.
Other centroid-based clustering methods include fuzzy c-means .
Connectivity-based clustering, also known as hierarchical clustering, groups data points together based on the proximity and connectivity of their attributes.
Simply put, this method determined clusters based on how close data points are to each other. The idea is that objects that are nearer are more closely related than those that are far from each other.
To implement connectivity-based clustering, you’ll need to determine which data points to use and measure their similarity or dissimilarity using a distance metric.
After that a connectivity measure (such as a graph or a network) is constructed to establish the relationships between the data points.
Finally, the clustering algorithm uses this connectivity information to group the data points into clusters that reflect their underlying similarities.
This is typically visualized in a dendrogram, which looks like a hierarchy tree (hence the name!).
Distribution-based clustering groups together data points based on their probability distribution.
Different from centroid-based clustering, it makes use of statistical patterns to identify clusters within the data.
Some common algorithms used in distribution-based clustering are:
In the Gaussian mixture model (GMM), clusters are determined by finding data points that have a similar distribution.
However, distribution-based clustering is highly prone to overfitting, where clustering is too reliant on the data set and cannot accurately make predictions.
Density-based clustering is a powerful unsupervised machine learning technique that allows us to discover dense clusters of data points in a data set.
Unlike other clustering algorithms, such as K-means and hierarchical clustering, density-based clustering can discover clusters of any shape, size, or density.
Density-based clustering is especially useful when working with datasets with noise or outliers or when we don’t have prior knowledge about the number of clusters in the data.
Here are some of its key features:
Here’s a list of some common density-based clustering algorithms:
Grid-based clustering partitions a high-dimensional data set into cells (disjoint sets of non-overlapping sub-regions).
Each cell is assigned a unique identifier called a cell ID, and all data points falling within a cell are considered part of the same cluster.
Grid-based clustering is an efficient algorithm for analyzing large multidimensional datasets as it reduces the time needed to search for nearest neighbors, which is a common step in many clustering methods.
There are several evaluation metrics for cluster analysis, and the selection of the appropriate metric depends on the type of clustering algorithm used and the understanding of the data.
Evaluation metrics can be generally split into two main categories:
Here are some common evaluation metrics for cluster analysis:
Extrinsic measures use ground truth or external information to evaluate the clustering algorithm’s performance.
Ground truth data is the label data that confirms the class or cluster in which each data point belongs.
Extrinsic measures can be used when we know the true labels and want to evaluate how well the clustering algorithm is performing.
Intrinsic measures are evaluation metrics for cluster analysis that only use the information within the data set.
In other words, they measure the quality of the clustering algorithm based on the data points’ relationships within the data set. They can be used when we do not have prior knowledge or labels of the data.
These evaluation metrics can help us compare the performance of different clustering algorithms and models, optimize clustering parameters, and validate the accuracy and quality of the clustering results.
Using multiple evaluation metrics to ensure the clustering algorithms’ effectiveness and make robust decisions for cluster analysis is always recommended.
Cluster analysis is a powerful unsupervised learning technique that is widely used in several industries and fields for data analysis. Here are some real-world applications of cluster analysis:
Companies leverage cluster analysis to segment their customer base into different groups.
Different customer attributes are analyzed, such as:
Businesses can better understand their customer base and design targeted marketing strategies to meet their requirements.
Medical practitioners use clustering techniques to segment images of infected tissues into different groups based on certain biomarkers like size, shape, and color.
This technique enables clinicians to detect early signs of cancer or other diseases.
Large companies like Netflix, Spotify, and YouTube utilize clustering algorithms to analyze user data and recommend movies or products.
This technique examines user behavior data like clicks, duration on specific content, and the number of replays.
These data points can be clustered to find insights into user preferences and improve existing recommendations to users.
Insurance companies utilize clustering analysis to segment various policies and customers’ risk levels.
By applying clustering techniques, an insurance company can better quantify the risk on their insurance policies and charge premiums based on potential risk.
Social media apps can collect huge amounts of data from their users. The recent discussion around apps like TikTok or Meta’s new Twitter-like Threads are good reminders of this.
By clustering and examining their social interactions, users can be segmented based on age, demography, or purchasing behavior to lead to targeted ads, improving the overall engagement of ad placements.
As you can see, cluster analysis is a powerful unsupervised learning technique.
To recap, here are some key takeaways:
What’s next? To get started with some practical work in data analytics, try out CareerFoundry’s free 5-day data analytics course, or better still, talk to one of our program advisors to see how a career in data could be for you.
For more related reading on other areas within data analytics, check out the following:
This article is part of:
Writer for The CareerFoundry Blog
Austin is a data science and tech writer with years of experience both as a data scientist and a data analyst in healthcare. Starting his tech journey with only a background in biological sciences, he now helps others make the same transition through his tech blog AnyInstructor.com. His passion for technology has led him to writing for dozens of SaaS companies, inspiring others and sharing his experiences.



CareerFoundry is an online school for people looking to switch to a rewarding career in tech. Select a program, get paired with an expert mentor and tutor, and become a job-ready designer, developer, or analyst from scratch, or your money back.